
사진에서 얼굴 데이터만 추출하기
관상으로 보는 범죄성향 테스트를 만들기 위해 범죄자 사진을 크롤링한 후 더욱 정확한 데이터 학습을 위해 얼굴 데이터만을 모으려고 한다. 이는 Google Cloud Vision API에서 제공하는 기능이기 때문에 이용해 보려고 한다.
만든 페이지가 궁금하다면 아래의 링크 클링
범죄성향 테스트
업로드한 사진은 저장되지 않습니다. 다른 사진으로 재시도
criminal.netlify.app
1. Vision API Enable 하기
- 아래의 에 링크로 들어가 VISION API를 사용하기 위해서는 해당 구글 클라우드 프로젝트에서 VISION API를 사용하도록 ENABLE 해줘야 한다.
https://cloud.google.com/vision/
Vision AI | 머신러닝을 통한 이미지 정보 도출 | Cloud Vision API | Google Cloud
AutoML Vision을 사용하여 클라우드나 에지 이미지에서 유용한 정보를 도출하거나 선행 학습된 Vision API 모델을 사용하여 감정, 텍스트 등을 인식합니다.
cloud.google.com
- VISION API를 ENABLE 하기 위해서는 아래 화면과 같이 구글 클라우드 콘솔 > API Manager 들어간 후 사용을 눌러 API Enable을 한다

2. Service Account 키 만들기
- 이 Vision API를 호출하기 위해서는 API 토큰이 필요한데, Service Account라는 JSON 파일을 다운로드하여서 사용한다.
- Vision API 관리는 눌러 관리 모드로 들어간다.
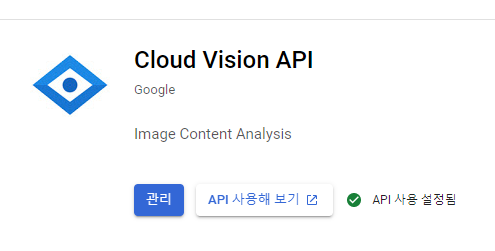
- 사용자 인증정보 -> 사용자 인증 정보 만들기 -> 서비스 계정 계정을 생성한다.
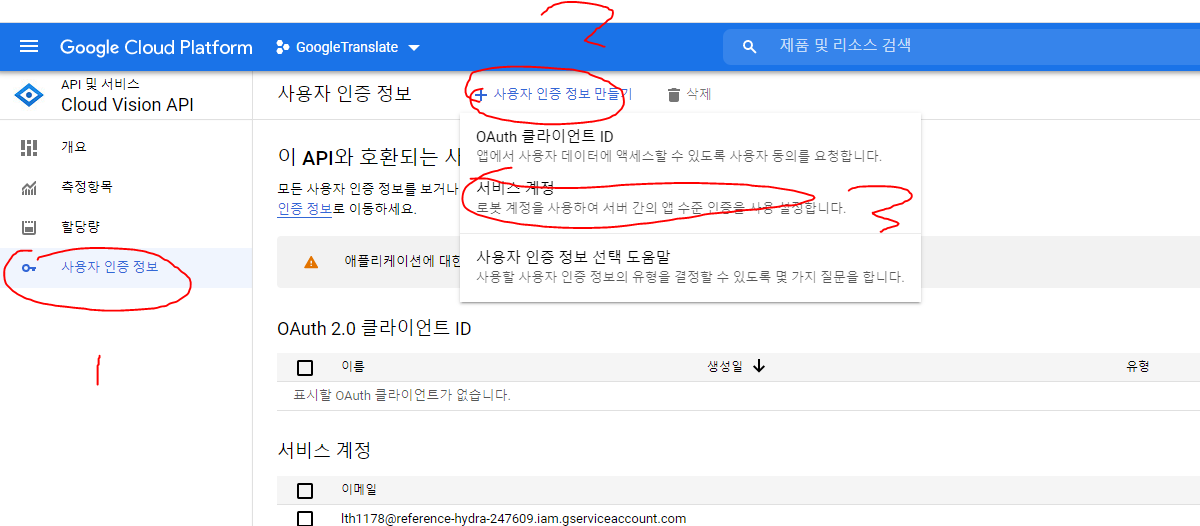
- 사용자 인증정보 -> 생성한 서비스 계정 클릭
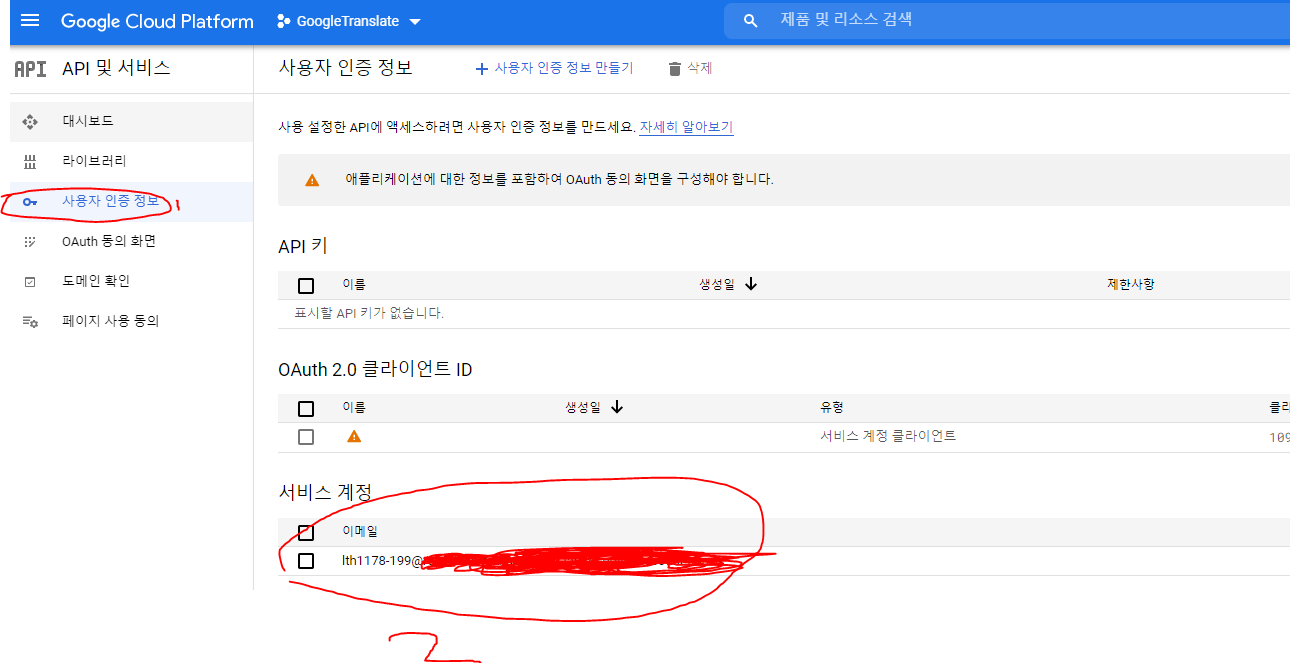
- 키 클릭

- 키 추가 -> 새키 만들기
- json 형식 선택 바로 다운이 완료된다. 이 KEY는 안전한 곳에 보관해야 한다.

3. Python Code를 이용하여 API 사용하기
- 나는 VSCode를 사용하였다.
- 아래의 코드를 사용하면 이미지에서 얼굴을 뽑아 올 수 있다.
!!!!!!!!!!!!!! 중요 이 코드는 얼굴인식을 위한 폴더 아래에 세부 폴더를 가지고 있다는 가정하에 작성된 코드이기 때문에 꼭 파일 아래에 파일들이 있어야 한다. 이해가 안 된다면 아래의 사진 참고 범죄자 사진 폴더 아래에 각각의 폴더가 있다.!!!!!!!!!
srcdir ="C:/Users/lth11/Desktop/내가 만약 범죄자라면/범죄자 사진" 이러한 형식으로!!
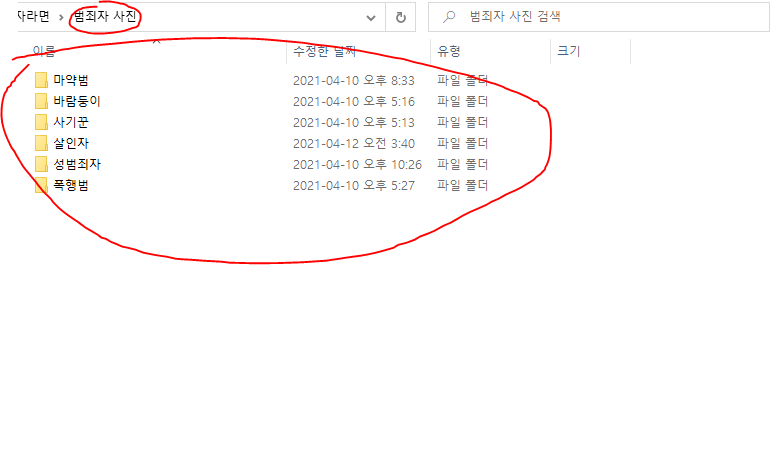
- 자신에게 맞는 코드로 쓰기 위해서는 3가지 부분을 변경해야 한다.
credentials = ServiceAccountCredentials.from_json_keyfile_name('여기에 위에서 저장한 key 위치/파일명.json', scopes=scopes)
-----------------------------------------------------------------------------------------------
srcdir= '얼굴인식을 원하는 이미지들이 들어있는 파일' # arg[1]
desdir = '얼굴 인식한 이미지들이 들어갈 파일' # arg[2]
maxnum = 500 # arg[3]
from googleapiclient import discovery
from oauth2client.client import GoogleCredentials
import sys
import io
import base64
from PIL import Image
from PIL import ImageDraw
from genericpath import isfile
import os
import hashlib
from oauth2client.service_account import ServiceAccountCredentials
NUM_THREADS = 10
MAX_FACE = 2
MAX_LABEL = 50
IMAGE_SIZE = 96,96
MAX_ROLL = 20
MAX_TILT = 20
MAX_PAN = 20
# index to transfrom image string label to number
global_label_index = 0
global_label_number = [0 for x in range(1000)]
global_image_hash = []
class FaceDetector():
def __init__(self):
# initialize library
#credentials = GoogleCredentials.get_application_default()
scopes = ['https://www.googleapis.com/auth/cloud-platform']
credentials = ServiceAccountCredentials.from_json_keyfile_name(
'C:/Users/lth11/Desktop/내가 만약 범죄자라면/Google_Vision_API_key/reference-hydra-247609-7cf3ee713856.json', scopes=scopes)
self.service = discovery.build('vision', 'v1', credentials=credentials)
#print ("Getting vision API client : %s" ,self.service)
#def extract_face(selfself,image_file,output_file):
def skew_angle(self):
return None
def detect_face(self,image_file):
try:
with io.open(image_file,'rb') as fd:
image = fd.read()
batch_request = [{
'image':{
'content':base64.b64encode(image).decode('utf-8')
},
'features':[
{
'type':'FACE_DETECTION',
'maxResults':MAX_FACE,
},
{
'type':'LABEL_DETECTION',
'maxResults':MAX_LABEL,
}
]
}]
fd.close()
request = self.service.images().annotate(body={
'requests':batch_request, })
response = request.execute()
if 'faceAnnotations' not in response['responses'][0]:
print('[Error] %s: Cannot find face ' % image_file)
return None
face = response['responses'][0]['faceAnnotations']
label = response['responses'][0]['labelAnnotations']
if len(face) > 1 :
print('[Error] %s: It has more than 2 faces in a file' % image_file)
return None
roll_angle = face[0]['rollAngle']
pan_angle = face[0]['panAngle']
tilt_angle = face[0]['tiltAngle']
angle = [roll_angle,pan_angle,tilt_angle]
# check angle
# if face skew angle is greater than > 20, it will skip the data
if abs(roll_angle) > MAX_ROLL or abs(pan_angle) > MAX_PAN or abs(tilt_angle) > MAX_TILT:
print('[Error] %s: face skew angle is big' % image_file)
return None
# check sunglasses
for l in label:
if 'sunglasses' in l['description']:
print('[Error] %s: sunglass is detected' % image_file)
return None
box = face[0]['fdBoundingPoly']['vertices']
left = box[0]['x']
top = box[1]['y']
right = box[2]['x']
bottom = box[2]['y']
rect = [left,top,right,bottom]
print("[Info] %s: Find face from in position %s and skew angle %s" % (image_file,rect,angle))
return rect
except Exception as e:
print('[Error] %s: cannot process file : %s' %(image_file,str(e)) )
def rect_face(self,image_file,rect,outputfile):
try:
fd = io.open(image_file,'rb')
image = Image.open(fd)
draw = ImageDraw.Draw(image)
draw.rectangle(rect,fill=None,outline="green")
image.save(outputfile)
fd.close()
print('[Info] %s: Mark face with Rect %s and write it to file : %s' %(image_file,rect,outputfile) )
except Exception as e:
print('[Error] %s: Rect image writing error : %s' %(image_file,str(e)) )
def crop_face(self,image_file,rect,outputfile):
global global_image_hash
try:
fd = io.open(image_file,'rb')
image = Image.open(fd)
# extract hash from image to check duplicated image
m = hashlib.md5()
with io.BytesIO() as memf:
image.save(memf, 'PNG')
data = memf.getvalue()
m.update(data)
image_hash = m.hexdigest()
if image_hash in global_image_hash:
print('[Error] %s: Duplicated image' %(image_file) )
return None
global_image_hash.append(image_hash)
crop = image.crop(rect)
im = crop.resize(IMAGE_SIZE,Image.ANTIALIAS)
im.save(outputfile,"JPEG")
fd.close()
print('[Info] %s: Crop face %s and write it to file : %s' %( image_file,rect,outputfile) )
return True
except Exception as e:
print('[Error] %s: Crop image writing error : %s' %(image_file,str(e)) )
def getfiles(self,src_dir):
files = []
for f in os.listdir(src_dir):
if isfile(os.path.join(src_dir,f)):
if not f.startswith('.'):
files.append(os.path.join(src_dir,f))
return files
# read files in src_dir and generate image that rectangle in face and write into files in des_dir
def rect_faces_dir(self,src_dir,des_dir):
if not os.path.exists(des_dir):
os.makedirs(des_dir)
files = self.getfiles(src_dir)
for f in files:
des_file = os.path.join(des_dir,os.path.basename(f))
rect = self.detect_face(f)
if rect != None:
self.rect_face(f, rect, des_file)
# read files in src_dir and crop face only and write it into des_dir
def crop_faces_dir(self,src_dir,des_dir,maxnum):
# training data will be written in $des_dir/training
# validation data will be written in $des_dir/validate
des_dir_training = os.path.join(des_dir,'training')
des_dir_validate = os.path.join(des_dir,'validate')
if not os.path.exists(des_dir):
os.makedirs(des_dir)
if not os.path.exists(des_dir_training):
os.makedirs(des_dir_training)
if not os.path.exists(des_dir_validate):
os.makedirs(des_dir_validate)
path,folder_name = os.path.split(src_dir)
label = folder_name
# create label file. it will contains file location
# and label for each file
training_file = open(des_dir+'/training_file.txt','a')
validate_file = open(des_dir+'/validate_file.txt','a')
files = self.getfiles(src_dir)
global global_label_index
cnt = 0
num = 0 # number of training data
for f in files:
rect = self.detect_face(f)
# replace ',' in file name to '.'
# because ',' is used for deliminator of image file name and its label
des_file_name = os.path.basename(f)
des_file_name = des_file_name.replace(',','_')
if rect != None:
# 99% of file will be stored in training data directory
if(cnt < 100):
des_file = os.path.join(des_dir_training,des_file_name)
# if we already have duplicated image, crop_face will return None
if self.crop_face(f, rect, des_file ) != None:
training_file.write("%s,%s,%d\n"%(des_file,label,global_label_index) )
num = num + 1
global_label_number[global_label_index] = num
cnt = cnt+1
if (num>=maxnum):
break
# 1% of files will be stored in validation data directory
else: # for validation data
des_file = os.path.join(des_dir_validate,des_file_name)
if self.crop_face(f, rect, des_file) != None:
validate_file.write("%s,%s,%d\n"%(des_file,label,global_label_index) )
cnt = cnt+1
if(cnt>100):
cnt = 0
#increase index for image label
global_label_index = global_label_index + 1
print('## label %s has %s of training data' %(global_label_index,num))
training_file.close()
validate_file.close()
def getdirs(self,dir):
dirs = []
for f in os.listdir(dir):
f=os.path.join(dir,f)
if os.path.isdir(f):
if not f.startswith('.'):
dirs.append(f)
return dirs
#output폴더도 input 폴더(input data image folder)처럼 나눠 저장 시키기
def get_output_dirs(self,src_dir, des_dir):
dirs = []
for f in os.listdir(src_dir):
f=os.path.join(des_dir,f)
if not os.path.exists(f):
os.makedirs(f)
if os.path.isdir(f):
if not f.startswith('.'):
dirs.append(f)
return dirs
def crop_faces_rootdir(self,src_dir,des_dir,maxnum):
# crop file from sub-directoris in src_dir
src_dirs = self.getdirs(src_dir)
des_dirs = self.get_output_dirs(src_dir, des_dir)
#list sub directory
for s, d in zip(src_dirs, des_dirs):
print('[INFO] : ### Starting cropping in directory %s ###'%s)
self.crop_faces_dir(s,d,maxnum)
#loop and run face crop
global global_label_number
print("number of datas per label ", global_label_number)
#usage
# arg[1] : src directory
# arg[2] : destination diectory
# arg[3] : max number of samples per class
srcdir= 'C:/Users/lth11/Desktop/내가 만약 범죄자라면/범죄자 사진' # arg[1]
desdir = 'C:/Users/lth11/Desktop/내가 만약 범죄자라면/범죄자_face_detect' # arg[2]
maxnum = 500 # arg[3]
detector = FaceDetector()
detector.crop_faces_rootdir(srcdir, desdir,maxnum)
#detector.crop_faces_dir(inputfile,outputfile)
#rect = detector.detect_face(inputfile)
#detector.rect_image(inputfile, rect, outputfile)
#detector.crop_face(inputfile, rect, outputfile)
Google Cloud Vision API는 유료이기 때문에 가격을 잘 알아봐야 한다.
여기서 사용한 API의 경우 한 달에 500장 무료 이후 1,000부터 2$의 비용이 청구된다.
참조 : https://bcho.tistory.com/1176
'딥러닝' 카테고리의 다른 글
| 젯슨 나노(Jetson Nano)로 인공지능 재난 군집드론 만들기 1편 (0) | 2021.08.19 |
|---|